Nginx 系统层面性能优化
优化 Nginx 性能是建立在 TCP 和 Linux 内核上。
Nginx 的系统层面性能优化
方法论
- 从软件层面提升硬件使用效率
- 增大 CPU 的利用率(惊群现象,就会导致 CPU 利用率增大)
- 增大内存的利用率
- 增大磁盘 IO 的利用率(可以使用缓存在内存中,不打开文件)
- 增大网络带宽的利用率
- 提升硬件规格
- 网卡:万兆网卡,例如 10G、25G、40G 等
- 磁盘:固态硬盘,关注 IOPS 和 BPS 指标
- CPU:更快的主频,更多的核心,更大的缓存,更优的架构
- 内存:更快的访问速度
- 超出硬件性能上限后使用 DNS,例如下图,通过 DNS 负载到不同的集群

高效使用CPU
增大 Nginx 使用 CPU 的有效时长
- 能够使用全面 CPU 资源
- master-worker 多进程架构
- worker 进程数量应大于等于 CPU 核数
- Nginx 进程间不做无用功浪费 CPU 资源
- worker 进程不应在繁忙时,主动让出 CPU
- worker 进程间不应由于争抢造成资源耗散
- worker 进程数量应当等于 CPU 核数(大于时,会出现争抢)
- worker 进程不应调用一些 API 导致主动让出 CPU(例如 阻塞 方法)
- 拒绝类似的第三方模块
- worker 进程间不应由于争抢造成资源耗散
- worker 进程不应在繁忙时,主动让出 CPU
- 不被其他进程争抢资源
- 提升优先级占用 CPU 更长的时间
- 减少操作系统上耗资源的非 Nginx 进程
设置 worker 进程的数量
https://nginx.org/en/docs/ngx_core_module.html#worker_processes
1 | Syntax: worker_processes number | auto; |
进程上下文切换
一个 CPU 就可以同时运行多个进程
- 宏观上并行,微观上串行
- 把进程的运行时间分为一段段的时间片
- OS 调度系统依次选择每个进程,最多执行时间片规定的时长

- 阻塞 API 引发的时间片内主动让出 CPU
- 速度不一致引发的阻塞 API
- 硬件执行速度不一致,例如 CPU 和磁盘(例如读取磁盘中的内容,此时 CPU 就会陷入等待,让出 CPU)
- 业务场景产生的阻塞 API
- 例如同步读网络报文(发出网络报文后,同步等待读取)
- 速度不一致引发的阻塞 API
保持进程在运行态
- R 运行:正在运行或在运行队列中等待
- S 中断:休眠中,受阻,在等待某个条件的形成或接受到信号
- D 不可中断:收到信号不唤醒和不可运行,进程必须等待直到有中断发生
- Z 僵死:进程已终止,但进程描述符不存在,直到父进程调用
wait4()系统调用后释放 - T 停止:进程收到 SIGSTOP,SIGSTP,SIGTIN,SIGTOU 信号后停止运行
减少进程间切换
- Nginx worker 尽可能的处于 R 状态
- R 状态的进程数量大于 CPU 核心时,负载急速增高

- 尽可能的减少进程间切换
- 进程间切换:是指 CPU 从一个进程或线程切换到另一个进程或线程
- 类别:
- 主动切换:例如阻塞 API
- 被动切换:时间片耗尽
cost: <5us,进程间切换的耗时
- 减少主动切换
- 减少被动切换
- 增大进程优先级(也就是增大时间片)
- 绑定 CPU
延迟处理新连接
1 | Syntax: listen address[:port] [default_server] [ssl] [http2 | quic] [proxy_protocol] [setfib=number] [fastopen=number] [backlog=number] [rcvbuf=size] [sndbuf=size] [accept_filter=filter] [deferred] [bind] [ipv6only=on|off] [reuseport] [so_keepalive=on|off|[keepidle]:[keepintvl]:[keepcnt]]; |
deferred:使用 TCP_DEFER_ACCEPT 延迟处理新连接
查看上下文切换次数
context-switch
vmstat![image-20240325151842364]()
dstat![image-20240325151912713]()
pidstat -w -p <pid>,针对进程cswch/s:主动切换
![image-20240325151952034]()



决定 CPU 时间片的大小
- Nice 静态优先级:
-20 -- 19,越大说明可以交由其他 CPU 执行,一般会将 Nginx 调小 - Priority 动态优先级:
0 - 139
#define DEFAULT_PRIO (MAX_RT_PRIO + NICE_WIDTH /2)

O1 调度算法(CFS)
- 优先级动态调整
- 幅度
+-5
- 依据
- CPU 消耗型进程
- IO 消耗型进程
- 幅度
- 分时:时间片
5ms-800ms(最小和最大)

设置 worker 进程的静态优先级
1 | Syntax: worker_priority number; |
多核间负载均衡
worker 进程间负载均衡
解决惊群问题的三种方式:

最终在 Linux 3.9 内核以上,选择 reuseport 特性

在 Kernel 层面,一个 socket 被每一个 worker 进程监听,并且做负载均衡。
网络层面优化
多队列网卡
多队列网卡对多核 CPU 的优化

- RSS:Receive Side Scaling:硬中断负载均衡(多个 CPU 可以同时并发处理硬中断)
- RPS:Receive Packet Steering:软中断负载均衡
- RFS:Receive Flow Steering(基于 RPS 做更好一层负载均衡)
根据具体场景,做对应调试。
提升 CPU 缓存命中率
跟 worker_cpu_affinity 指令相关

进程绑定 CPU 的好处是避免 CPU 上的缓存失效
1 | Syntax: worker_cpu_affinity cpumask ...; |
Numa 架构

NUMA(Non-Uniform Memory Access,非一致性内存访问)是一种计算机系统设计架构,旨在解决多处理器系统中内存访问速度不一致的问题。在 NUMA 架构中,系统中的不同处理器核心(CPU)通过不同的内存控制器访问内存,导致不同内存区域的访问速度可能不同。
例如 NUMA 系统中每个处理器核心连接到不同的内存区域,因此访问本地内存比访问远程内存更快。因此,在 NUMA 系统中,内存被划分为不同的节点,每个节点包含处理器核心和与之关联的本地内存。处理器可以更快地访问其本地节点的内存,而访问其他节点的内存则需要经过更慢的跨节点通信。为了最大程度地减少跨节点访问带来的性能损失,NUMA 系统会尽可能将数据放置在本地节点,以减少跨节点通信。
1 | # numactl --hardware |
查看命中率
1 | # numastat |
当缓存命中率低,可以通过修改 numa 结构,例如禁止访问远端,例如关闭 numa 架构。
TCP 层面优化
TCP 连接

SYN_SENT 状态 :客户端
net.ipv4.tcp_syn_retries = 6:主动建立连接时,发 SYN 的重试次数
net.ipv4.ip_local_port_range = 32768 60999:建立连接时的本地端口可用范围
主动建立连接时应用层超时时间
https://nginx.org/en/docs/http/ngx_http_proxy_module.html#proxy_connect_timeout
1 | Syntax: proxy_connect_timeout time; |
https://nginx.org/en/docs/stream/ngx_stream_proxy_module.html#proxy_connect_timeout
1 | Syntax: proxy_connect_timeout time; |
SYN_RCVD 状态:服务器端
net.ipv4.tcp_max_syn_backlog:SYN_RCVD 状态连接的最大个数(三次握手未完成,半连接的方式)
net.ipv4.tcp_synack_retries:被动建立连接时,发 SYN/ACK 的重试次数
服务器端处理三次握手

建立 TCP 连接优化
应对 SYN 攻击
攻击者短时间伪造不同 IP 地址的 SYN 报文,快速占满 backlog 队列,使服务器不能为正常用户服务。
net.core.netdev_max_backlog:接受自网卡、但未被内核协议栈处理的报文队列长度
net.ipv4.tcp_max_syn_backlog:SYNC_RCVD 状态连接的最大个数
net.ipv4.tcp_abort_on_overflow:超出处理能力时,对新来的 SYN 直接回包 RST,丢弃连接
除此之外,还有一个方法 tcp_syncookies
正常流程如下:通过 SYN 队列存储收到的 SYN 报文连接信息;通过 Accept 队列存储返回 ACK 报文的连接,让应用层处理。

当应用程序过慢,导致 Accept 队列满,因此 SYN 队列中的数据取出来也无法存放,导致连接无法建立。

使用 cookie,当 Accept 队列满,使用 cookie


句柄数的上限
Linux 系统中,一切皆文件,句柄数上限可能会限制连接数上限。
操作系统全局
fs.file-max- 操作系统可使用的最大句柄数
- 使用
fs.file-nr可以查看当前已分配、正使用、上限fs.file-nr = 21632 0 40000500
限制用户
/etc/security/limits.confroot soft nofile 65535:进程在运行时可以修改的链接数,一定要小于hardroot hard nofile 65535:强制的,真实的链接数
限制进程
https://nginx.org/en/docs/ngx_core_module.html#worker_rlimit_nofile
1
2
3Syntax: worker_rlimit_nofile number;
Default: —
Context: main设置 worker 进程最大连接数量
https://nginx.org/en/docs/ngx_core_module.html#worker_connections
1
2
3
4Syntax: worker_connections number;
Default:
worker_connections 512;
Context: events设置单个工作进程可以打开的最大同时连接数。包括 Nginx 与上游、下游间的连接。
两个队列的长度
- SYN 队列未完成握手:
net.ipv4.tcp_max_syn_backlog = 262144 - ACCEPT 队列已完成握手:
net.core.somaxconn,系统级最大backlog队列长度
1
2
3
4
5
6Syntax: listen address[:port] [default_server] [ssl] [http2 | quic] [proxy_protocol] [setfib=number] [fastopen=number] [backlog=number] [rcvbuf=size] [sndbuf=size] [accept_filter=filter] [deferred] [bind] [ipv6only=on|off] [reuseport] [so_keepalive=on|off|[keepidle]:[keepintvl]:[keepcnt]];
listen port [default_server] [ssl] [http2 | quic] [proxy_protocol] [setfib=number] [fastopen=number] [backlog=number] [rcvbuf=size] [sndbuf=size] [accept_filter=filter] [deferred] [bind] [ipv6only=on|off] [reuseport] [so_keepalive=on|off|[keepidle]:[keepintvl]:[keepcnt]];
listen unix:path [default_server] [ssl] [http2 | quic] [proxy_protocol] [backlog=number] [rcvbuf=size] [sndbuf=size] [accept_filter=filter] [deferred] [bind] [so_keepalive=on|off|[keepidle]:[keepintvl]:[keepcnt]];
Default:
listen *:80 | *:8000;
Context: serverbacklog:在listen()调用中设置backlog参数,该参数限制了挂起连接队列的最大长度。默认情况下,在 FreeBSD、DragonFly BSD 和 macOS 上,backlog 设置为 -1,在其他平台上设置为 511。- SYN 队列未完成握手:
TCP Fast Open

将发送数据的过程省掉,在响应 SYN 报文时,同时发送 cookie,客户端保存 cookie,在后续发送数据时,携带 cookie,不需要重复建立 TCP。

滑动窗口
TCP 建立连接后,开始传输数据。这个时候滑动窗口机制会影响效率,以及调整 TCP 缓冲区大小。

通告窗口

TCP 报文中的 Window 字段,表示当前窗口大小。
发送 TCP 消息

第 5、6 步使用阻塞模型
TCP 消息接收

TCP 消息接收发生 CS(进程休眠,导致进程切换)

TCP 消息接收时新报文到达

Nginx 的潮湿指令与滑动窗口
两次读操作间的超时
1 | Syntax: client_body_timeout time; |
两次写操作的超时
1 | Syntax: send_timeout time; |
以上两者兼具
1 | Syntax: proxy_timeout timeout; |
丢包重传
TCP 有重传机制,可同限制重传次数提升性能

TCP 缓冲区

1 | Syntax: listen address[:port] [default_server] [ssl] [http2 | quic] [proxy_protocol] [setfib=number] [fastopen=number] [backlog=number] [rcvbuf=size] [sndbuf=size] [accept_filter=filter] [deferred] [bind] [ipv6only=on|off] [reuseport] [so_keepalive=on|off|[keepidle]:[keepintvl]:[keepcnt]]; |
rcvbuf=size:设置侦听套接字的接收缓冲区大小(SO_RCVBUF 选项)。
sndbuf=size:设置侦听套接字的发送缓冲区大小(SO_SNDBUF 选项)。
使用读写缓冲区配置,操作系统的配置则会失效。
调整接收窗口与应用缓存

BDP
BDP(带宽时间级,也就是意味着网络中有多少传输中的字节数,也就是接收窗口) = 带宽 x 时延,吞吐量 = 窗口/时延

禁用 Nagle 算法
尽量将小报文合并成大报文
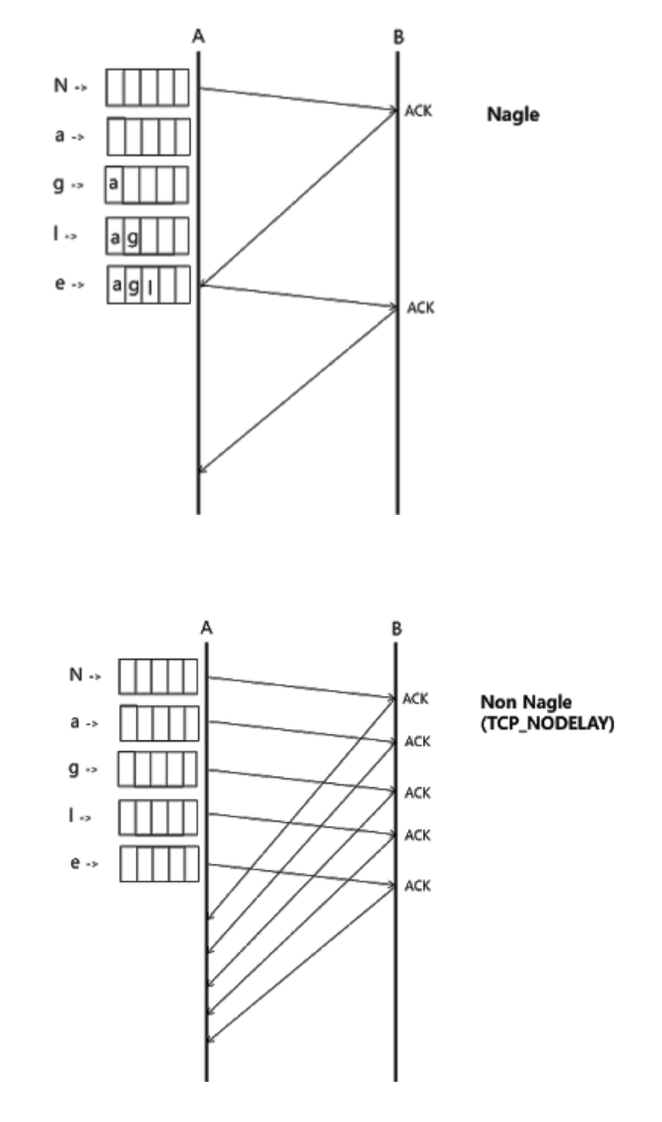

Nginx 也可以避免发送小报文
https://nginx.org/en/docs/http/ngx_http_core_module.html#postpone_output
1 | Syntax: postpone_output size; |
启用 CORK 算法
仅针对 sendfile on 开启时有效,完全禁止小报文的发送,提升网络效率
1 | Syntax: tcp_nopush on | off; |
流量控制
滑动窗口用于控制发送方发送数据的速率,以匹配接收方的接收能力,而拥塞窗口用于控制数据在网络中的传输速率,以避免网络拥塞。
- 拥塞窗口
- 发送方主动限制流量
- 通告窗口(对端接收窗口)
- 接收方限制流量
- 实际流量
- 拥塞窗口与通告窗口的最小值
拥塞处理:


RTT 与 RTO

- RTT:Round Trip Time,指的是数据从发送端发送到接收端,再从接收端发送回确认的整个往返时间
- 时刻变化
- 组成:
- 物理链路传输时间
- 末端处理时间
- 路由器排队处理时间
- 知道 RTO
- RTO:Retransmission TimeOut,是指在TCP协议中,当发送方发送数据后,等待接收确认的超时时间。如果在RTO时间内未收到确认,则发送方会重新发送数据。
- 正确的应对丢包
在TCP通信中,发送方会根据RTT和RTO的信息来调整数据传输的速率和重传机制,以确保数据传输的可靠性和效率。合理设置RTO时间是保证数据传输可靠性的关键之一,过短的RTO可能导致不必要的重传,而过长的RTO可能延迟数据传输的恢复。
TCP 的 Keep-alive 功能
应用场景:
- 检测实际断掉的连接,及时释放 TCP 资源(与 HTTP 中的 keep-alive 的复用连接将短连接复用成长连接不同)
- 用于维护与客户端间的防火墙有活跃网络包

关闭 TCP 连接
TCP 连接的过程

当应用程序关闭连接,被动方才会从 CLOSE_WAIT 状态变为 LAST_ACK 状态。
被动关闭连接端
- CLOSE_WAIT 状态
- 应用进程没有及时响应对端关闭连接(如果有大量的连接处于这个状态,那么是应用程序出现 bug,收到 FIN 后,没有调用
close()方法)
- 应用进程没有及时响应对端关闭连接(如果有大量的连接处于这个状态,那么是应用程序出现 bug,收到 FIN 后,没有调用
- LAST_ACK 状态
- 等待接受主动关闭操作系统发来的针对 FIN 的 ACK 报文(如果有大量的连接处于这个状态,代表迟迟没有收到对端的 ACK 报文)
主动关闭连接端的状态
- FIN_WAIT1 状态(发送 FIN 报文后的状态)
net.ipv4.tcp_orphan_retries = 0,发送 FIN 报文的重试次数,0 相当于 8 (FIN 报文可能被丢掉)
- FIN_WAIT2 状态(接受到对端 ACK 报文后的状态)
net.ipv4.tcp_fin_timeout = 60,保持在 FIN_WAIT2 状态的时间(也就是等待对方的 FIN 报文)
- TIME_WAIT 状态(接受到对端 FIN 报文后的状态)
TIME_WAIT
MSL(Maximum Segment Lifetime):报文最大生存时间
TIME_WAIT 状态过短或者不存在会怎样:
维持 2MSL 时长的 TIME_WAIT 状态,保证至少一次报文的往返时间内端口是不可复用的。

tcp_tw_reuse


lingering_close 延迟关闭的意义
当 Nginx 处理完成调用 close 关闭连接后,若接收缓冲区仍然收到客户端发来的内容,则服务器会向客户端发送 RST 包关闭连接,导致客户端由于收到RST而忽略了http response。
配置指令

以 RST 代替正常的四次握手关闭连接

应用层面优化
TLS/SSL 优化
TLS/SSL 优化握手性能

TLS/SSL 中的会话票证 tickets

HTTP 长连接
优点:
- 减少握手次数
- 通过减少并发连接数减少了服务器资源的消耗
- 降低 TCP 拥塞控制的影响
对下游和上游的 HTTP 长连接配置

gzip 压缩
通过实时压缩 HTTP 包体,提升网络传输效率。默认编译进 Nginx
https://nginx.org/en/docs/http/ngx_http_gzip_module.html
1 | Syntax: gzip on | off; |
设置压缩哪些请求的响应

设置是否压缩上游的响应

其他压缩参数

升级更高效的 HTTP2 协议
- 向前兼容 http/1.x 协议
- 传输效率大幅度提升
磁盘 IO 的优化


可以通过 fio 测试性能
减少磁盘 IO


直接 IO
绕开磁盘高速缓存

左边正常读取数据;右边直接 IO 读取和写入数据,也就是读和写都绕过内核缓冲区。
适合于大文件:直接 IO

异步 IO

左边传统方式;右边异步 IO,调用 read 方法时,用户程序可以处理其他任务,不会陷入阻塞。
使用方式:

异步读 IO 线程池
编译时加入 --with-threads

在异步读取 IO 时,避免进程进入等待,会派生出线程处理任务队列中的任务,等待任务执行完,丢给 worker 进程继续执行。
线程池:做静态资源读取服务时使用,避免内存不够 inode 失效导致的读取异步 IO。
Thread Pools in NGINX Boost Performance 9x!
定义线程池:

异步 IO 中的缓存:

减少磁盘读写次数
empty_gif 模块

access 日志的压缩

error.log 日志输出内存

syslog 协议
避免将日志写入磁盘,而是通过网络协议写入到 syslog 服务器


rsyslog 与 Nginx

sendfile 零拷贝提升性能
- 减少进程间切换
- 减少内存拷贝次数
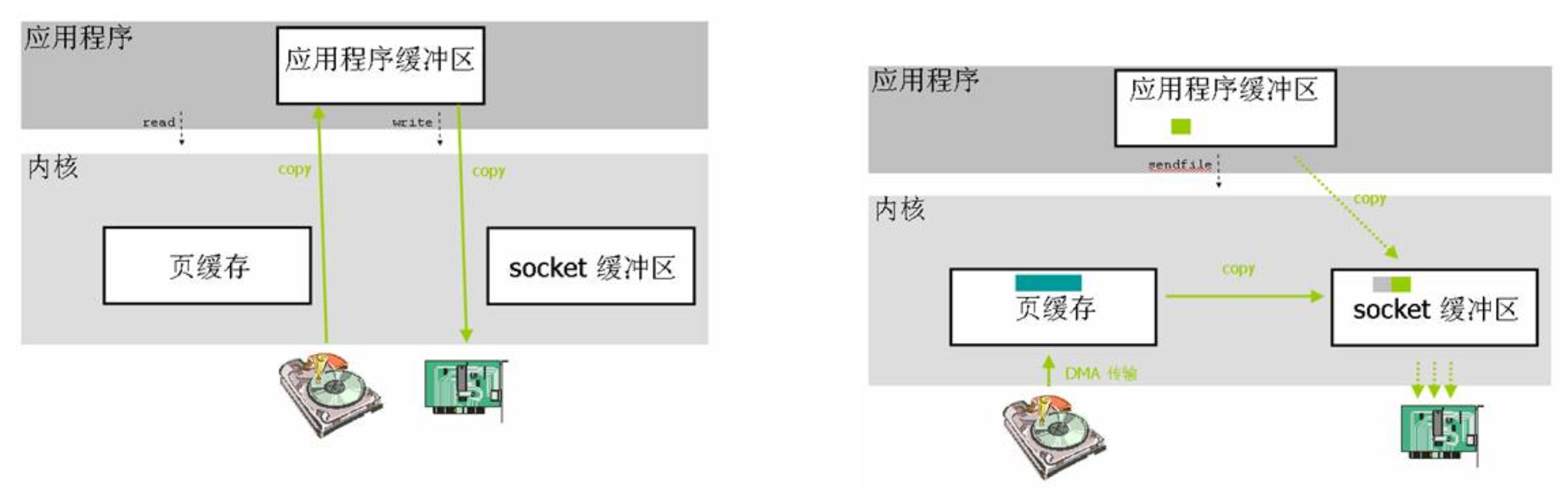
正常情况下,当需要响应磁盘中的内容时,应用程序从磁盘中读取数据,是先要读取到内核的页缓存,然后再读取到应用程序缓存区,也就是经过两次拷贝,发送出去也是同样的过程,首先从应用程序缓冲区拷贝到 socket 缓冲区,然后被网卡发送出去。
零拷贝是应用程序通过指令,让内核将磁盘中的数据读取到页缓存(也可以通过 DMA 高速传输),然后拷贝到 socket 缓冲区,交由网卡处理。
同时开启 sendfile、直接 IO、异步 IO:但是直接 IO 会禁用 sendfile

gzip_static 模块
如果启用了 gzip,需要压缩,那么数据一定会读取到缓存中进行压缩。
https://nginx.org/en/docs/http/ngx_http_gzip_static_module.html
检测到同名 .gz 文件时,response 中以 gzip 相关 header 返回 .gz 文件的内容。默认不编译进 Nginx
always:不管客户端是否支持,都发送压缩过的文件。
1 | Syntax: gzip_static on | off | always; |
gunzip 模块
当客户端不支持 gzip 时,且磁盘上仅有压缩文件,则实时解压缩并将其发送给客户端。默认不编译进 Nginx
https://nginx.org/en/docs/http/ngx_http_gunzip_module.html
1 | Syntax: gunzip on | off; |
tcmalloc
谷歌提供的内存分配库
- 更快的内存分配器
- 并发能力强于
glibc- 并发线程数越多,性能越好
- 减少内存碎片
- 擅长管理小块内存
- 并发能力强于
https://goog-perftools.sourceforge.net/doc/tcmalloc.html
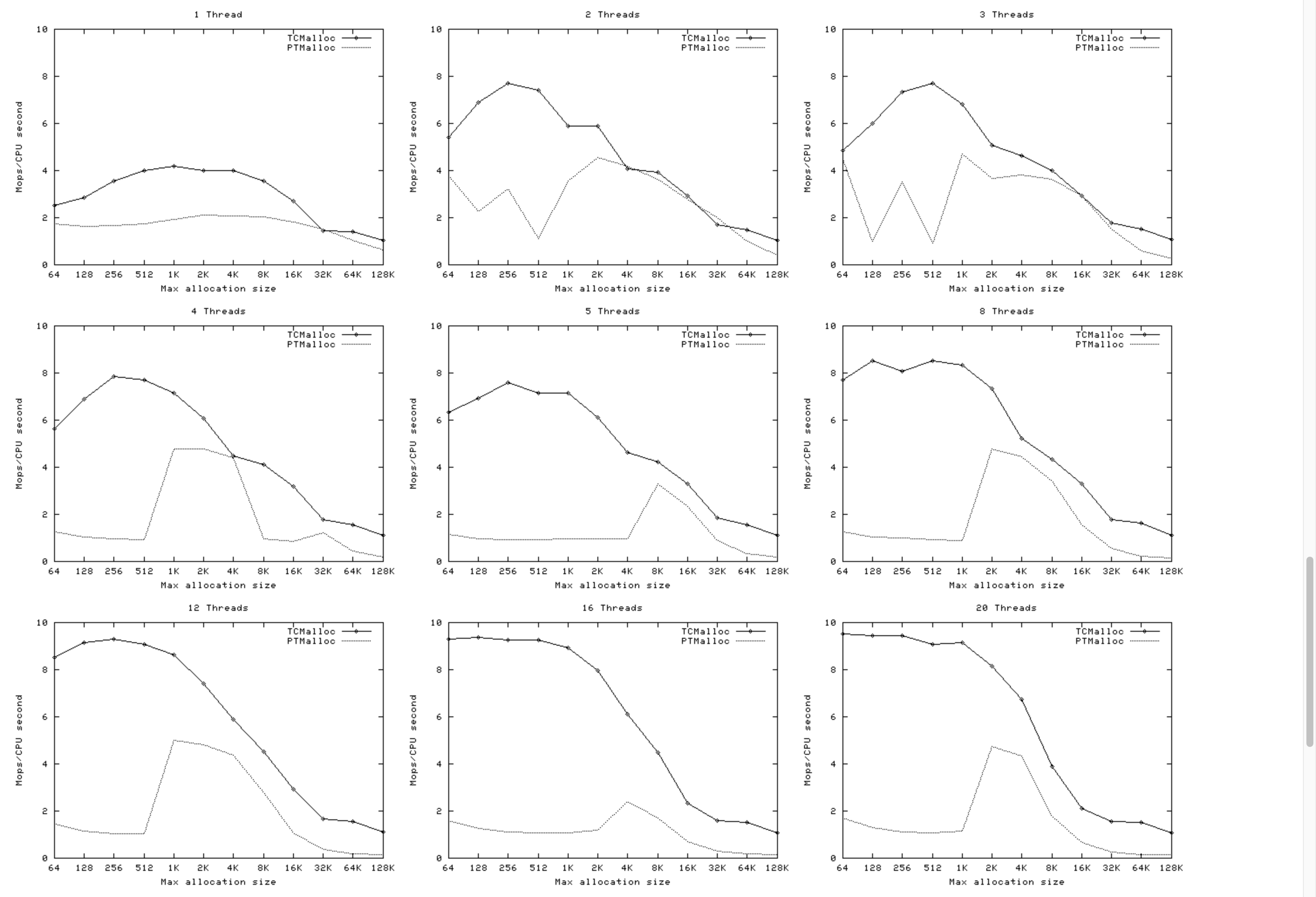
线程数对比
下面的图表显示了TCMalloc与PTMalloc2在几个不同指标上的性能。首先是每秒经过的总操作次数(百万)与最大分配大小之间的关系,针对不同线程数量。
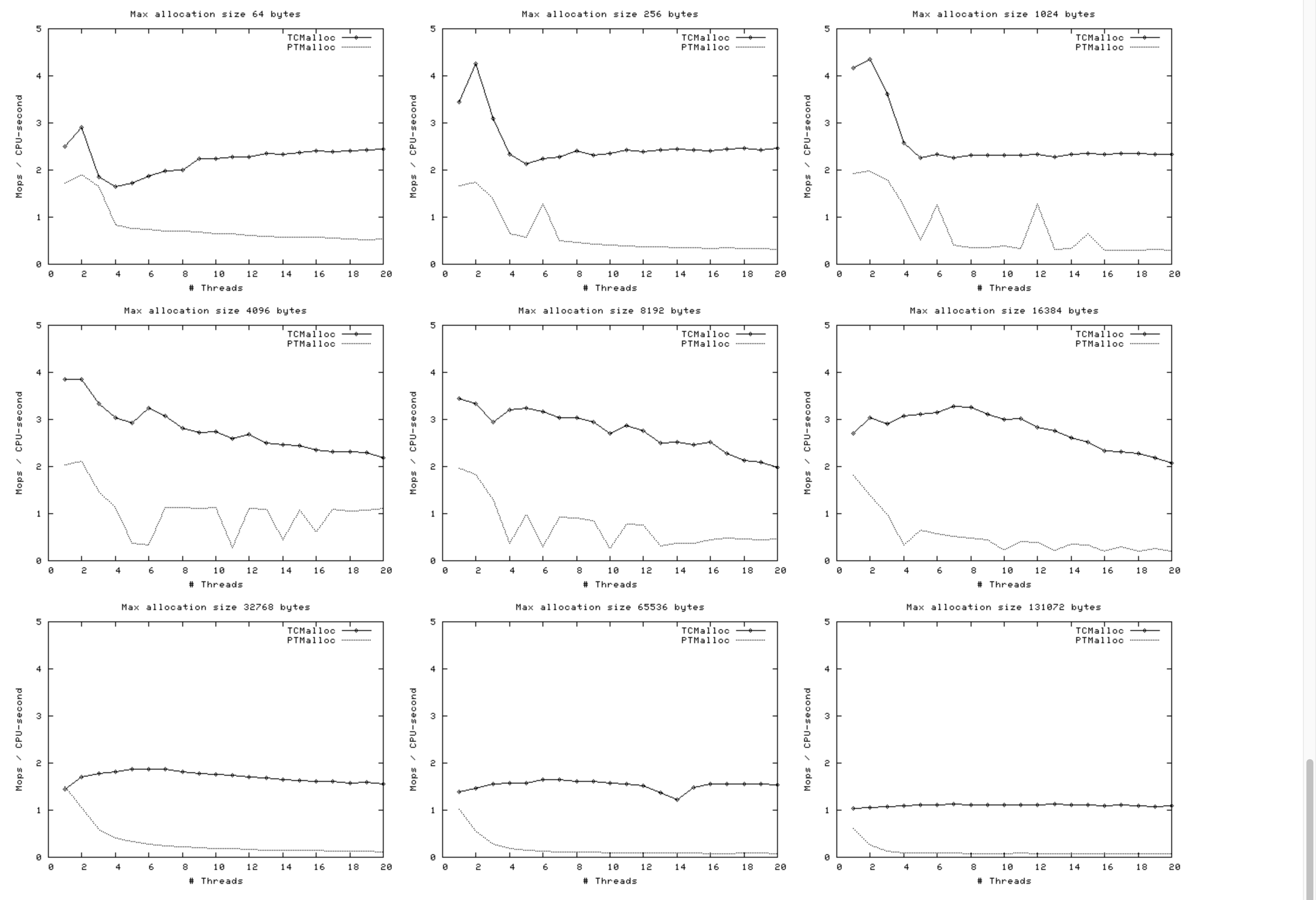
内存大小对比
库:
https://github.com/gperftools/gperftools

使用 gperftools 定位 Nginx 性能问题

文本风格结果

stub_status 模块监控 Nginx
https://nginx.org/en/docs/http/ngx_http_stub_status_module.html
通过 HTTP 接口,实时检测 Nginx 的连接状态。
统计数据存放于共享内存中,所以统计值包含所有 worker 进程,且执行 reload 不会导致数据清零,但热升级会导致数据清零。默认没有编译进 Nginx
1 | Syntax: stub_status; |
模块的监控项
